Though a well known term in the data science industry, Log Loss is not very well known to the average user of this web site. Let this blog serve as a quick introduction to the term, it’s meaning, and all of the ways that it can be applied to our data.
An Introduction to Log Loss
Log Loss has increasingly become the go-to metric for judging the accuracy of binary outcomes. One could probably tie this to the increasing popularity of the Kaggle, which is a web site that hosts competitions for data scientists. Regardless, we use this metric quite often on DRatings, so it is important for us to give a little bit of an explainer of the metric here.
Breaking Down Log Loss
If one reads nothing else, then it’s important to know that the analyst is always shooting to have the LOWEST Log Loss possible. The best log loss that one can have is zero, and the worst log loss runs to negative infinity. This is how the breakdown for Log Loss looks as a formula.
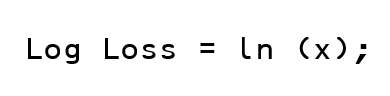
The Log Loss function
Consider two teams, Team A and Team B, playing each other in a contest.
x = probability of “Team A” to win.
If “Team A” wins, Log Loss = ln(x).
If “Team B” wins, Log Loss = ln(1-x).
The table below shows what Log Loss looks like at a variety of different endpoints.
| med K's | mean K's | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | >9 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 3.536 | 11.95% | 15.52% | 15.56% | 13.94% | 11.66% | 9.26% | 7.05% | 5.16% | 3.63% | 2.46% | 3.80% |
| 3.5 | 4.015 | 8.78% | 13.06% | 14.36% | 13.81% | 12.25% | 10.24% | 8.16% | 6.23% | 4.56% | 3.20% | 5.35% |
| 4 | 4.466 | 6.53% | 10.90% | 13.00% | 13.33% | 12.47% | 10.93% | 9.08% | 7.20% | 5.46% | 3.97% | 7.14% |
| 4.25 | 4.7025 | 5.59% | 9.86% | 12.23% | 12.96% | 12.46% | 11.18% | 9.49% | 7.68% | 5.94% | 4.39% | 8.22% |
| 4.5 | 4.939 | 4.77% | 8.88% | 11.46% | 12.53% | 12.37% | 11.37% | 9.86% | 8.13% | 6.41% | 4.83% | 9.40% |
| 4.75 | 5.165 | 4.12% | 8.04% | 10.75% | 12.08% | 12.23% | 11.48% | 10.15% | 8.52% | 6.83% | 5.23% | 10.57% |
| 5 | 5.391 | 3.51% | 7.19% | 9.97% | 11.56% | 12.01% | 11.53% | 10.41% | 8.92% | 7.28% | 5.67% | 11.95% |
| 5.25 | 5.6255 | 2.98% | 6.41% | 9.22% | 11.01% | 11.73% | 11.52% | 10.62% | 9.27% | 7.71% | 6.11% | 13.42% |
| 5.5 | 5.86 | 2.54% | 5.70% | 8.49% | 10.43% | 11.40% | 11.45% | 10.77% | 9.59% | 8.11% | 6.54% | 14.99% |
| 5.75 | 6.087 | 2.16% | 5.07% | 7.81% | 9.86% | 11.03% | 11.32% | 10.87% | 9.85% | 8.48% | 6.95% | 16.60% |
| 6 | 6.315 | 1.84% | 4.50% | 7.15% | 9.28% | 10.63% | 11.15% | 10.91% | 10.07% | 8.82% | 7.35% | 18.32% |
| 6.25 | 6.548 | 1.56% | 3.96% | 6.51% | 8.68% | 10.19% | 10.92% | 10.89% | 10.24% | 9.13% | 7.74% | 20.17% |
| 6.5 | 6.781 | 1.32% | 3.49% | 5.91% | 8.09% | 9.72% | 10.64% | 10.83% | 10.37% | 9.41% | 8.12% | 22.11% |
| 7 | 7.237 | 0.94% | 2.69% | 4.84% | 6.97% | 8.76% | 9.99% | 10.56% | 10.48% | 9.84% | 8.77% | 26.15% |
| 7.5 | 7.701 | 0.67% | 2.04% | 3.89% | 5.90% | 7.76% | 9.21% | 10.12% | 10.41% | 10.11% | 9.32% | 30.58% |
| 8 | 8.158 | 0.47% | 1.54% | 3.10% | 4.94% | 6.77% | 8.37% | 9.54% | 10.16% | 10.21% | 9.72% | 35.18% |
| 8.5 | 8.62 | 0.33% | 1.14% | 2.44% | 4.06% | 5.82% | 7.48% | 8.84% | 9.76% | 10.14% | 9.97% | 40.03% |
| 9 | 9.079 | 0.23% | 0.84% | 1.89% | 3.30% | 4.93% | 6.59% | 8.07% | 9.22% | 9.90% | 10.05% | 44.97% |
| 9.5 | 9.54 | 0.16% | 0.61% | 1.45% | 2.65% | 4.12% | 5.71% | 7.25% | 8.57% | 9.51% | 9.98% | 50.00% |
We can further explain with the following two examples. Let us assume that we give Team A a 70% chance to win, and they do win. Looking back at the table, this would mean that our Log Loss for this observation is -0.3567. Now, let’s assume that under the same projection that Team A loses. Our Log Loss for this observation is now -1.2040.
What is a Good Log Loss?
It completely depends! Evaluating Log Loss can be very tricky. At the end of the day, Log Loss is used to judge which model is the best. The very worst that a model should do over the long term is -0.6931. Why? Because an analyst that is simply guessing, or picking Team A to win at 50% will end up with a result of -0.6931 if they win or lose.
In sports or analyses where the true probabilities are closer to 50%, it’s much harder to get a low Log Loss. As of this writing, our MLB Baseball Predictions have a Log Loss of -0.6755 over 3,000+ games. Compare this to our -0.622 Log Loss over 267 games in the NFL which has much less parity.
The end goal for any sports projection formula is to beat the Log Loss of the sportbook’s closing line on a consistent basis. Any analytic model that could do this would justifiably be able to be profitable betting sports over time.
Pros/Cons
A few benefits and drawbacks of the Log Loss function as it relates to judging accuracy.
Pros
- Very strong with a lot of observations: When the number of observations gets into the thousands and more, this tool works very well.
- It’s the industry standard: Everyone it data science uses or is familiar with Log Loss.
Cons
- Doesn’t work well with a small number of observations: Generally, this can be said about any method, but it’s worth noting.
- Beware of correlations and ability to game: This is one of my frustrations with a lot of Kaggle’s competitions. For instance, in the NCAA ML Competition, one is allowed two entries. What is stopping someone from creating an entry that “picks a winner” by giving them a 100% chance across the board. Clearly, no team has a 100% chance to win any game and if this team losses, then the entry is out. But, if the entry hits, then that’s six out of 64 observations with a Log Loss of 0. This entry is bound to place high on the leader board if the rest of the analytic model is sound.
More Reading
For more information on Log Loss, Making Sense of Log Loss is a wonderful reference. Those who really want to get down in the weeds will enjoy Understanding binary cross-entropy / log loss: a visual explanation. Happy reading!